前言
本文主要是纪录近期实现的一个增强学习的实例,一直再说增强学习,原理大家也都理解,可是受制于图形学、算法等,直观的增强学习的效果还是很难看到的,多亏了ale,结合opencv可以直观的看到增强学习的效果,下面将详细介绍DQN实现atari在mac上的实现。
参考资料
当然是参考经典的论文Playing Atari with Deep Reinforcement Learning
基本实现github:https://github.com/gliese581gg/DQN_tensorflow
ALE环境介绍
小时候都玩过射击、乒乓球等简单小游戏,其实就是atari小游戏,就是控制左右上下等来躲避怪物,具体的可以参考http://www.arcadelearningenvironment.org/,现在比较好的就是这个平台开源了,可以在电脑上来模拟这些小游戏,可以通过api的方式输入action来控制,输出下一帧的图片以及reward和是否结束等,reward可以灵活设置,比如没有terminal就是1,terminal了就是0。
如何安装
git clone https://github.com/mgbellemare/Arcade-Learning-Environment
mkdir build && cd build; cmake -DUSE_SDL=OFF -DUSE_RLGLUE=OFF -DBUILD_EXAMPLES=ON ..;make -j4
sudo python setup.py
这样就安装了ALE的python版本。
如何使用ALE?
需要安装cv2,并且下载一个游戏的rom文件,这里用breakout来做实验。大概的实现如下代码。
论文结构
qlearning
强化学习中有状态(state)、动作(action)、奖赏(reward)这三个要素。训练的主体需要根据当前状态来采取动作,获得相应的奖赏之后,再去改进这些动作,使得下次再到相同状态时,智能体能做出更优的动作。这个过程就是qlearning,这其中的核心就是q表的训练,q表就是状态、动作和奖赏的映射表,处在某个状态中,该选择哪个action,直接查表即可,当然这时候的q表已经非常准确了。m个状态,n个action,对应的reward表可以表示如下所示:
| s/a | A1 | A2 | … | An |
|---|---|---|---|---|
| S1 | R11 | R12 | … | R1n |
| S2 | R21 | R22 | … | R2n |
| … | … | … | … | … |
| Sm | Rm1 | Rm2 | … | Rmn |
一般例子里用小孩学习还是看电视,最后做推理,那个里面看电视和学习就是两个action,状态就是有限的几个状态。flappybird里的action就是上下,状态可以用小鸟距离前一个下桶,上桶的距离以及地面的距离这三个值来作为状态衡量,而atari里action显然就是玩游戏的那几个手柄键(最多18个action),状态是什么呢?状态就是原始的图片,所以这是个非常庞大和复杂的Q表,通过输入状态(原始图片信息)和action查到Q值,所以这是个训练函数的过程,可以通过svm等线性模型实现,这里我们使用深度神经网络来模拟这个函数,就是论文中提到的dqn。
loss与learning
Q表里的是q值,即收益值,该值与当前的直接reward以及下一个状态最大值有直接关系,reward表示当前状态下的收益,游戏里可以就表示两种状态,生存或者死亡,0和1即可。表示如下:
qlearning中的Q值可用函数表示成
$ Q(s,a) = \max \limits_{a} {r + \gamma maxQ(s’,a’)|s,a} $
结合代码来看,下个状态的最大值通过replay来获取,即上一个参数下(老的theta), 该状态下的最大值q_t,这样就得到了相当于supervised里的label Q(s,a),与旧的函数里算的Q值做差值即产生了loss, 其实可以看到状态的reward再不断的学习进来,并且未来的前途也会考量,但是最终都是由本地的reward这个实实在在的东西得来的,不死即是目标。
q_t细究
q_t是当前状态下一阶段(给定的action到达的下一状态,在online时已经发生的状态,不一定时最有的action)的最大收益值,通过older的网络在online时尝试各种(action)后获得。如下的计算网络Loss(用于更新网络参数)可以看出,yj是label,Q_pred是older网络(当前网络,更新参数前)根据action算出的值。
replay
一般的增强学习里都是需要replay,棋类游戏的自我对弈也是获取replay的方式,简单的游戏里状态的确是有限的,比如象棋,但是像围棋这种状态很多,大概$2^{19*19}$,action又较多361,象棋要少很多,这种情况下,罗列状态做成map映射是不可能的,可以采用深度神经网络的方式来处理原始状态的情况,但是label比较难获取,如何自我训练获取label?
这里就用到replay机制,将Q(S,a)分解成当前的可看到的reward以及下一个状态最大的Q值(可以用旧的网络直接计算),下一个状态如何获取?如果遍历当前所有的action显得比较笨重,这样体现replay的用处了,先跑一遍,在回头来一下,所以是off-policy。为何不是on-policy?我的感觉主要是随机,因为当下训练的batch就是随机抽出来的,而非on-policy实时关联的,实时policy会导致问题,”For example, if the maximizing action is to move left then the training samples will be dominated by samples from the left-hand side; if the maximizing action then switches to the right then the training distribution will also switch. It is easy to see how unwanted feedback loops may arise and the parameters could get stuck in a poor local minimum, or even diverge catastrophically”。online通过$\epsilon -greedy$的方式获取较均匀的状态,这里不表。
DQN架构详解
DQN的实现是使用tensorflow,输入是当前的图像特征、当前状态的奖励、当前状态是否是终止状态、下一步的action以及action对应的下一个状态的最大收益,最大收益是通过replay的方式可以直接获取的,也就是之前提到的$\theta _{i-1}$。通过tensorboard将基本的构图画了出来,如下所示:
整体架构,又输入、卷积层、全连接层、loss、train目标层构成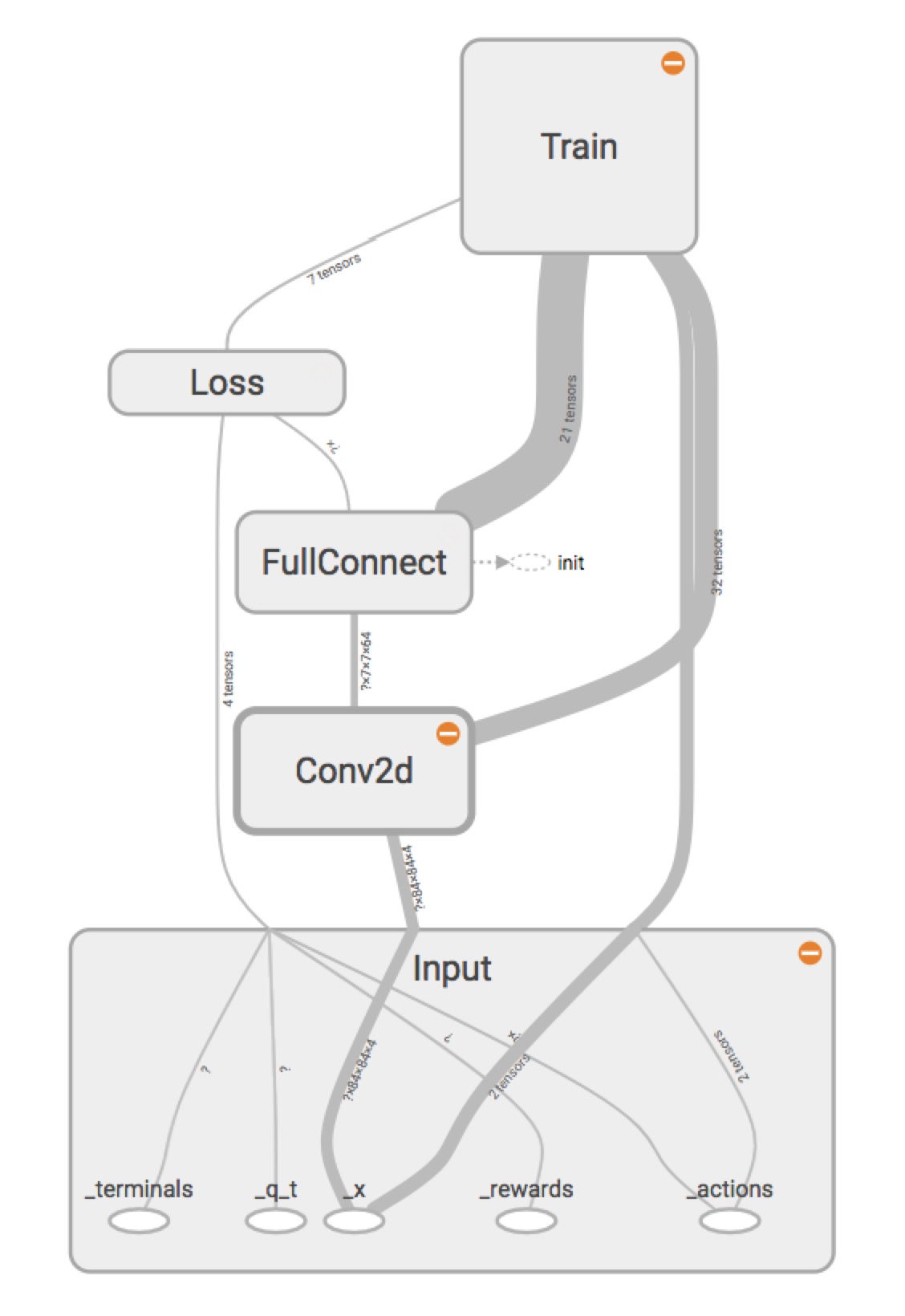
三个卷积、relu如下所示: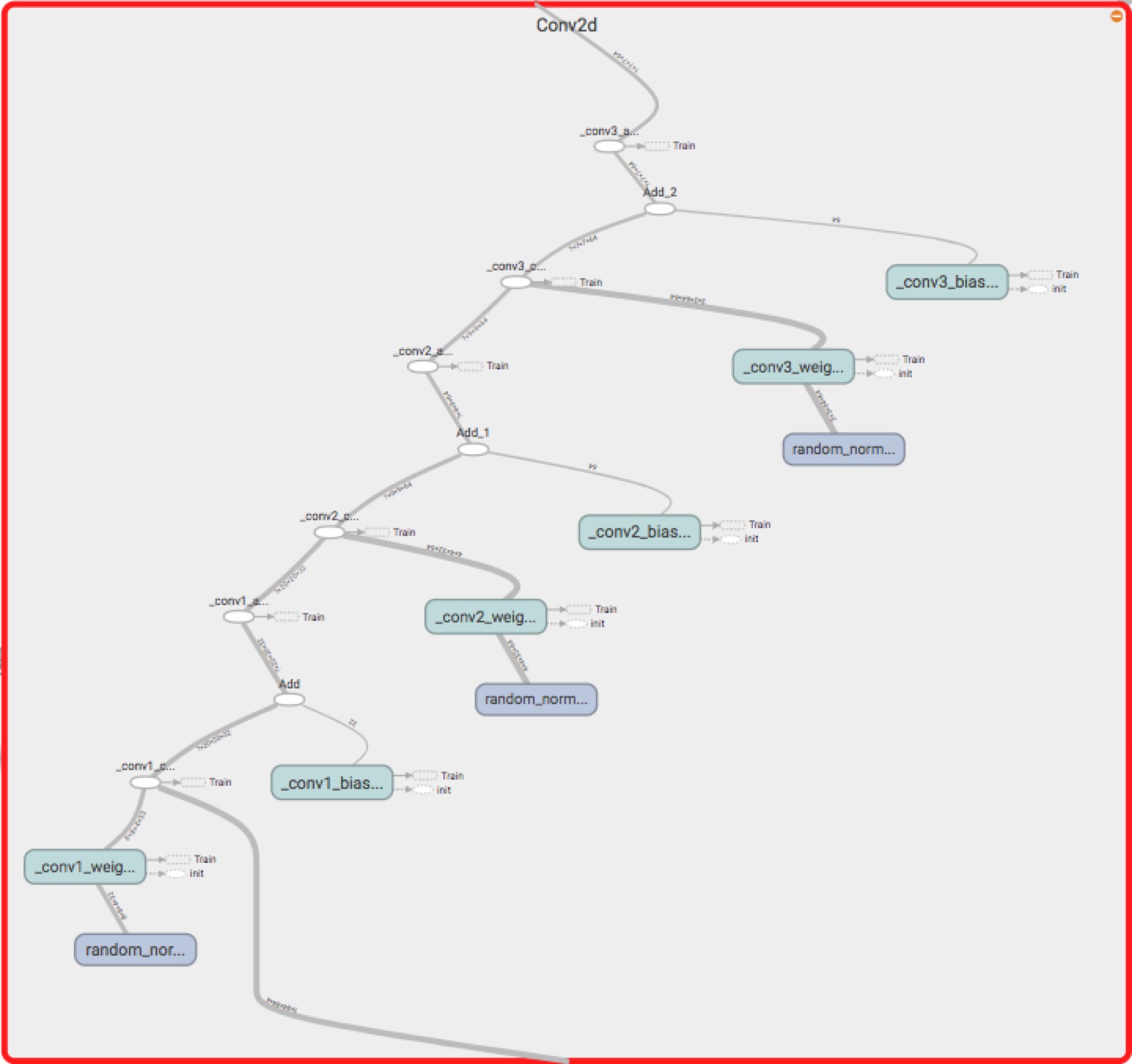
两个全连接层如下: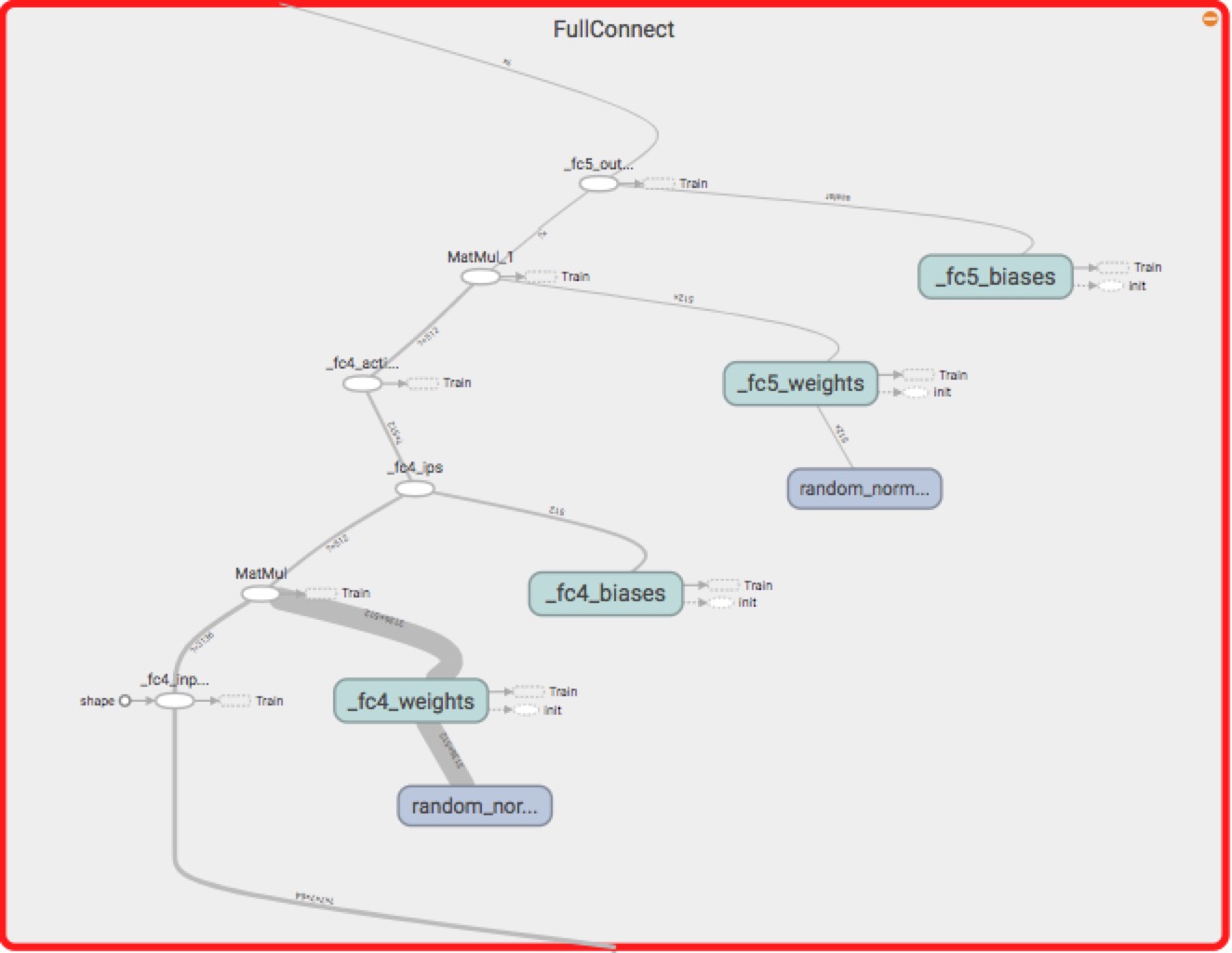
loss层如下: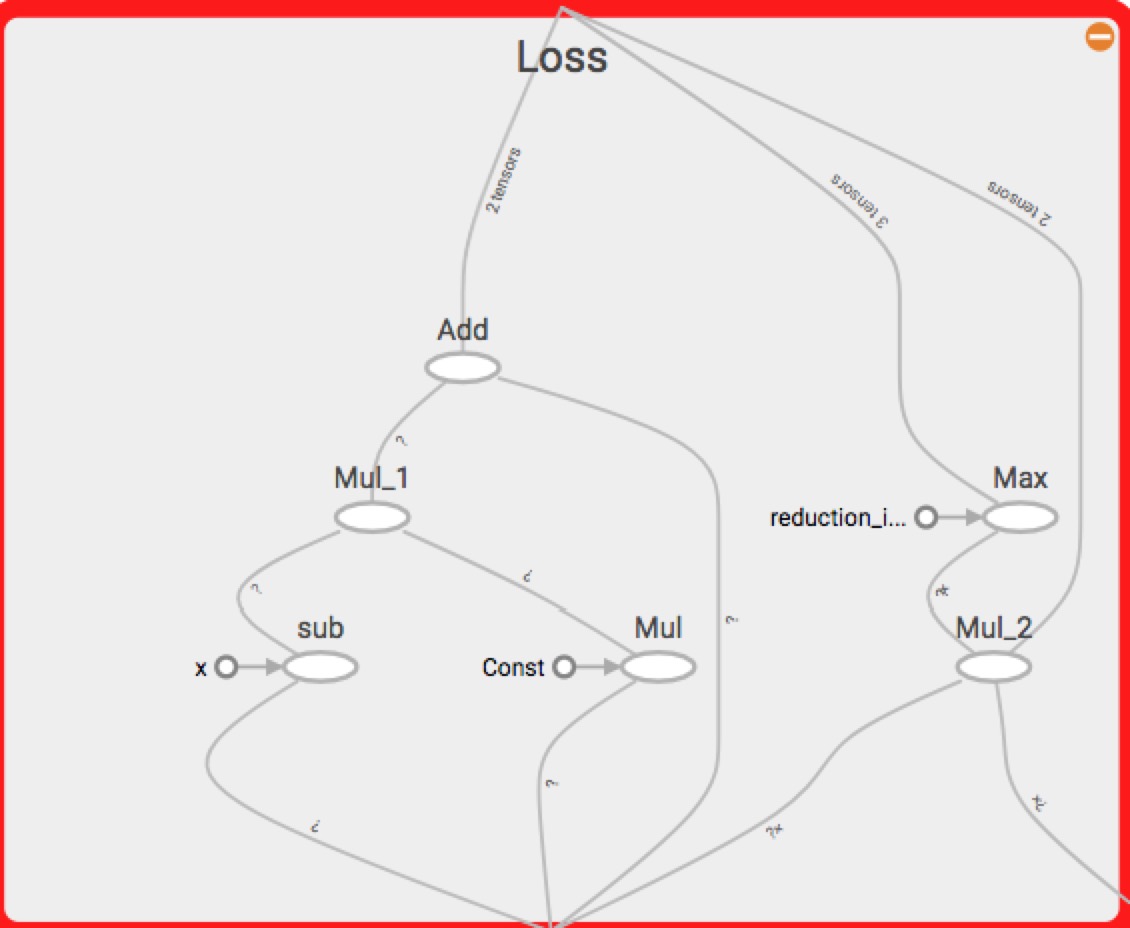
训练效果
github中给出了一个链接,https://www.youtube.com/watch?v=GACcbfUaHwc,基本上就是这个效果,训练了两天以上后,我自己也训练了一个版本,不过只训练了一个晚上,效果已经非常不错了,感觉已经超过我的水平了,大体的方向性还是很明显的。

